What are the nodes in a Visual RA?
Quote from AntC on March 21, 2020, 3:27 amQuote from dandl on March 20, 2020, 11:10 pmAn AST does not represent data flow, it is merely a diagrammatic representation of function application. LISP without the parentheses. Wrong paradigm.
No, but it can be subverted to become dataflow-like. Given an EXTEND expression like p := 2 * (y + 3), it obviously converts to an AST, but the AST is notionally akin to a dataflow something like:
[y] --\ [+] --\ [3] --/ [*] --> [p} [2] --------/I.e., the value of y and the value of the literal 3 flow into the '+' operator, the result of which flows into the '*' operator, etc.
I understood what you meant, but it doesn't help. If the nodes and edges are constrained to operate on tables or even rows, you can't easily subvert them to operate on simple values. Certainly Knime won't allow it.
I'm having trouble, em visualising what your visual programming language looks like. Do you have some examples in mind?
Why do you want to show anything operating on 'simple values' (presumably you mean scalars)? Can't it be relations/attributes all the way down?
So far, my efforts at using text expressions hinder transparency. With the EXTEND model you see the output of a node that adds a new value, but you can't see what it's inputs are except by parsing the text. I don't find that a sweet spot at all.
Different strokes for different folks, I guess.
I'm pondering a node that acts purely as a function. It takes a relation as input but chooses which attributes it will use as inputs/arguments. It outputs a relation comprising only the function arguments and result. It does not EXTEND an input relation, it merely computes a NEW VALUE. Then as per A and HHT, you are free to JOIN that output as you wish.
I don't mind the computed function being very simple and just picked from a list, or arbitrarily complex and written using a sub-language, as long as the inputs and outputs are transparent.
Yes, calling functions is reasonable, though if you integrate editing them into the environment you pretty much wind up with something like Rel's visual query language -- nodes for RA operators and text for scalar (and certain sub-) expressions.
The point is: getting away from the EXTEND paradigm.
I'm not seeing why you want to get away from EXTEND/what's wrong with it/why you prefer Alice's new. EXTEND is a form of JOIN (says Appendix A), typically joining a 'stored relation' with an 'algorithmic relation' -- to use the terms in HHT 1975. More specifically, the 'new' attribute(s) (the ones in the algorithmic relation not in common with the stored) are the target of a Functional Dependency from those that are in common -- to interpret HHT a little. Then EXTEND is two relations in, one relation out, as with any JOIN. For visual presentation you could represent the Dependency arrow in the heading of the algorithmic relation.
As per App-A and HHT you can model TIMES as a relation operator: relation in, relation out.
- The input is some relation with one or more numeric attributes, say
{{ A=3,B=7,other... },{ A=2,B=11,other...}, ...}- The output is
{{ A=3, B=7, C=21 },{ A=2,B=11,C=22}, ...}The output is join-compatible with the input.
{A, B, other ...} -----\ [JOIN]---> {A, B, C, other ...} {A, B -> C} -----/The output is join-compatible with the input because that's true of the result of any JOIN (assuming its operands are join-compatible).
The
{ A, B -> C}relation can include any arbitrary calculation getting fromA, BtoC, not merely TIMES. It can be the Cartesian product of{A INT} x {B INT} x {C INT}with a constraint thatC == f(A, B). Or put lambda notation in the relation:
{A, B, C == (A x B)}-- Vadim's QBQL does something like this
{ λ A, B -> C := (A x B)}
Quote from dandl on March 20, 2020, 11:10 pmAn AST does not represent data flow, it is merely a diagrammatic representation of function application. LISP without the parentheses. Wrong paradigm.
No, but it can be subverted to become dataflow-like. Given an EXTEND expression like p := 2 * (y + 3), it obviously converts to an AST, but the AST is notionally akin to a dataflow something like:
[y] --\ [+] --\ [3] --/ [*] --> [p} [2] --------/I.e., the value of y and the value of the literal 3 flow into the '+' operator, the result of which flows into the '*' operator, etc.
I understood what you meant, but it doesn't help. If the nodes and edges are constrained to operate on tables or even rows, you can't easily subvert them to operate on simple values. Certainly Knime won't allow it.
I'm having trouble, em visualising what your visual programming language looks like. Do you have some examples in mind?
Why do you want to show anything operating on 'simple values' (presumably you mean scalars)? Can't it be relations/attributes all the way down?
So far, my efforts at using text expressions hinder transparency. With the EXTEND model you see the output of a node that adds a new value, but you can't see what it's inputs are except by parsing the text. I don't find that a sweet spot at all.
Different strokes for different folks, I guess.
I'm pondering a node that acts purely as a function. It takes a relation as input but chooses which attributes it will use as inputs/arguments. It outputs a relation comprising only the function arguments and result. It does not EXTEND an input relation, it merely computes a NEW VALUE. Then as per A and HHT, you are free to JOIN that output as you wish.
I don't mind the computed function being very simple and just picked from a list, or arbitrarily complex and written using a sub-language, as long as the inputs and outputs are transparent.
Yes, calling functions is reasonable, though if you integrate editing them into the environment you pretty much wind up with something like Rel's visual query language -- nodes for RA operators and text for scalar (and certain sub-) expressions.
The point is: getting away from the EXTEND paradigm.
I'm not seeing why you want to get away from EXTEND/what's wrong with it/why you prefer Alice's new. EXTEND is a form of JOIN (says Appendix A), typically joining a 'stored relation' with an 'algorithmic relation' -- to use the terms in HHT 1975. More specifically, the 'new' attribute(s) (the ones in the algorithmic relation not in common with the stored) are the target of a Functional Dependency from those that are in common -- to interpret HHT a little. Then EXTEND is two relations in, one relation out, as with any JOIN. For visual presentation you could represent the Dependency arrow in the heading of the algorithmic relation.
As per App-A and HHT you can model TIMES as a relation operator: relation in, relation out.
- The input is some relation with one or more numeric attributes, say
{{ A=3,B=7,other... },{ A=2,B=11,other...}, ...}- The output is
{{ A=3, B=7, C=21 },{ A=2,B=11,C=22}, ...}The output is join-compatible with the input.
{A, B, other ...} -----\
[JOIN]---> {A, B, C, other ...}
{A, B -> C} -----/
The output is join-compatible with the input because that's true of the result of any JOIN (assuming its operands are join-compatible).
The { A, B -> C} relation can include any arbitrary calculation getting from A, B to C, not merely TIMES. It can be the Cartesian product of {A INT} x {B INT} x {C INT} with a constraint that C == f(A, B). Or put lambda notation in the relation:
{A, B, C == (A x B)} -- Vadim's QBQL does something like this
{ λ A, B -> C := (A x B)}
Quote from dandl on March 21, 2020, 5:38 amI'm having trouble, em visualising what your visual programming language looks like. Do you have some examples in mind?
Attached. I have examples for the listed queries, but not one for EXTEND yet.
Why do you want to show anything operating on 'simple values' (presumably you mean scalars)? Can't it be relations/attributes all the way down?
I agree, and that's the Knime model.
The point is: getting away from the EXTEND paradigm.
I'm not seeing why you want to get away from EXTEND/what's wrong with it/why you prefer Alice's new. EXTEND is a form of JOIN (says Appendix A), typically joining a 'stored relation' with an 'algorithmic relation' -- to use the terms in HHT 1975. More specifically, the 'new' attribute(s) (the ones in the algorithmic relation not in common with the stored) are the target of a Functional Dependency from those that are in common -- to interpret HHT a little. Then EXTEND is two relations in, one relation out, as with any JOIN. For visual presentation you could represent the Dependency arrow in the heading of the algorithmic relation.
I've implemented EXTEND and it works fine, except there is still a heap of work to do in connecting up all the functions. My perception is that it doesn't look 'right', because the new column appears magically, and you can't easily see what it depends on.
I'm exploring choices that look to me a better fit into the node-and-edge paradigm.
As per App-A and HHT you can model TIMES as a relation operator: relation in, relation out.
- The input is some relation with one or more numeric attributes, say
{{ A=3,B=7,other... },{ A=2,B=11,other...}, ...}- The output is
{{ A=3, B=7, C=21 },{ A=2,B=11,C=22}, ...}The output is join-compatible with the input.
{A, B, other ...} -----\ [JOIN]---> {A, B, C, other ...} {A, B -> C} -----/The output is join-compatible with the input because that's true of the result of any JOIN (assuming its operands are join-compatible).
No you missed the point. The
{A,B,C}output is join-compatible with the{A,B,lots of other attributes}input. It only works that way if the function node echoes its input arguments with their original names.The
{ A, B -> C}relation can include any arbitrary calculation getting fromA, BtoC, not merely TIMES. It can be the Cartesian product of{A INT} x {B INT} x {C INT}with a constraint thatC == f(A, B). Or put lambda notation in the relation:
{A, B, C == (A x B)}-- Vadim's QBQL does something like this
{ λ A, B -> C := (A x B)}That's the whole idea: the function node shows its arguments and return value(s) as its output, so it can be joined as needed. But the implementation of that function can be arbitrarily complex, either a canned function or a piece of scripting written to use named arguments (not attribute names, as in App-A).
I'm having trouble, em visualising what your visual programming language looks like. Do you have some examples in mind?
Attached. I have examples for the listed queries, but not one for EXTEND yet.
Why do you want to show anything operating on 'simple values' (presumably you mean scalars)? Can't it be relations/attributes all the way down?
I agree, and that's the Knime model.
The point is: getting away from the EXTEND paradigm.
I'm not seeing why you want to get away from EXTEND/what's wrong with it/why you prefer Alice's new. EXTEND is a form of JOIN (says Appendix A), typically joining a 'stored relation' with an 'algorithmic relation' -- to use the terms in HHT 1975. More specifically, the 'new' attribute(s) (the ones in the algorithmic relation not in common with the stored) are the target of a Functional Dependency from those that are in common -- to interpret HHT a little. Then EXTEND is two relations in, one relation out, as with any JOIN. For visual presentation you could represent the Dependency arrow in the heading of the algorithmic relation.
I've implemented EXTEND and it works fine, except there is still a heap of work to do in connecting up all the functions. My perception is that it doesn't look 'right', because the new column appears magically, and you can't easily see what it depends on.
I'm exploring choices that look to me a better fit into the node-and-edge paradigm.
As per App-A and HHT you can model TIMES as a relation operator: relation in, relation out.
- The input is some relation with one or more numeric attributes, say
{{ A=3,B=7,other... },{ A=2,B=11,other...}, ...}- The output is
{{ A=3, B=7, C=21 },{ A=2,B=11,C=22}, ...}The output is join-compatible with the input.
{A, B, other ...} -----\ [JOIN]---> {A, B, C, other ...} {A, B -> C} -----/The output is join-compatible with the input because that's true of the result of any JOIN (assuming its operands are join-compatible).
No you missed the point. The {A,B,C} output is join-compatible with the {A,B,lots of other attributes} input. It only works that way if the function node echoes its input arguments with their original names.
The
{ A, B -> C}relation can include any arbitrary calculation getting fromA, BtoC, not merely TIMES. It can be the Cartesian product of{A INT} x {B INT} x {C INT}with a constraint thatC == f(A, B). Or put lambda notation in the relation:
{A, B, C == (A x B)}-- Vadim's QBQL does something like this
{ λ A, B -> C := (A x B)}
That's the whole idea: the function node shows its arguments and return value(s) as its output, so it can be joined as needed. But the implementation of that function can be arbitrarily complex, either a canned function or a piece of scripting written to use named arguments (not attribute names, as in App-A).
Uploaded files: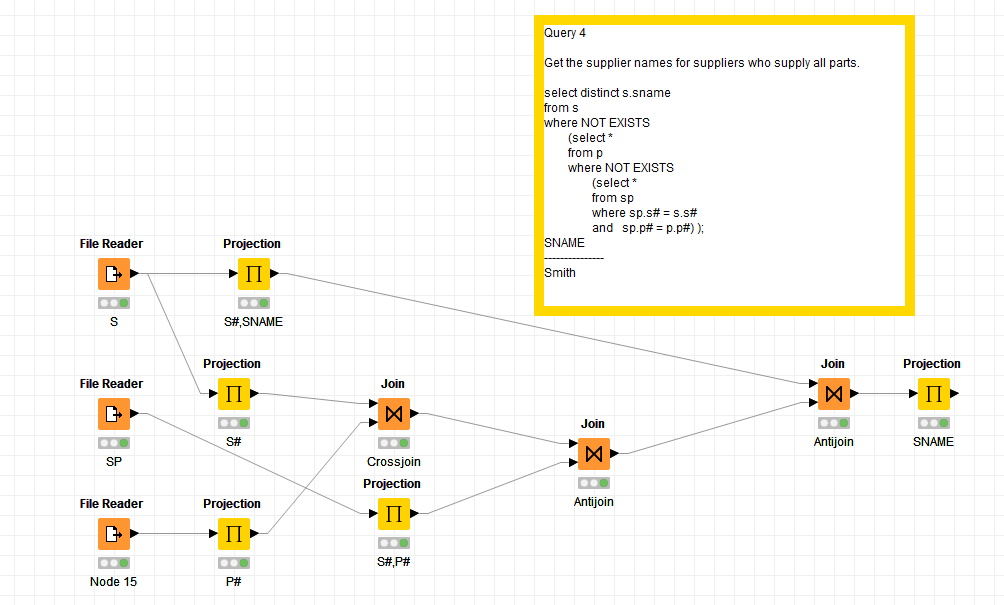
Quote from Dave Voorhis on March 21, 2020, 8:52 amQuote from dandl on March 20, 2020, 11:10 pmAn AST does not represent data flow, it is merely a diagrammatic representation of function application. LISP without the parentheses. Wrong paradigm.
No, but it can be subverted to become dataflow-like. Given an EXTEND expression like p := 2 * (y + 3), it obviously converts to an AST, but the AST is notionally akin to a dataflow something like:
[y] --\ [+] --\ [3] --/ [*] --> [p} [2] --------/I.e., the value of y and the value of the literal 3 flow into the '+' operator, the result of which flows into the '*' operator, etc.
I understood what you meant, but it doesn't help. If the nodes and edges are constrained to operate on tables or even rows, you can't easily subvert them to operate on simple values. Certainly Knime won't allow it.
Ah, a limitation of KNIME.
So far, my efforts at using text expressions hinder transparency. With the EXTEND model you see the output of a node that adds a new value, but you can't see what it's inputs are except by parsing the text. I don't find that a sweet spot at all.
Different strokes for different folks, I guess.
I'm pondering a node that acts purely as a function. It takes a relation as input but chooses which attributes it will use as inputs/arguments. It outputs a relation comprising only the function arguments and result. It does not EXTEND an input relation, it merely computes a NEW VALUE. Then as per A and HHT, you are free to JOIN that output as you wish.
I don't mind the computed function being very simple and just picked from a list, or arbitrarily complex and written using a sub-language, as long as the inputs and outputs are transparent.
Yes, calling functions is reasonable, though if you integrate editing them into the environment you pretty much wind up with something like Rel's visual query language -- nodes for RA operators and text for scalar (and certain sub-) expressions.
The point is: getting away from the EXTEND paradigm. As per App-A and HHT you can model TIMES as a relation operator: relation in, relation out.
- The input is some relation with one or more numeric attributes, say
{{ A=3,B=7,other... },{ A=2,B=11,other...}, ...}- The output is
{{ A=3, B=7, C=21 },{ A=2,B=11,C=22}, ...}The output is join-compatible with the input.
I didn't know EXTEND was a paradigm; I thought it was an operator. Are you trying to get away from it because of other KNIME limitations?
Quote from dandl on March 20, 2020, 11:10 pmAn AST does not represent data flow, it is merely a diagrammatic representation of function application. LISP without the parentheses. Wrong paradigm.
No, but it can be subverted to become dataflow-like. Given an EXTEND expression like p := 2 * (y + 3), it obviously converts to an AST, but the AST is notionally akin to a dataflow something like:
[y] --\ [+] --\ [3] --/ [*] --> [p} [2] --------/I.e., the value of y and the value of the literal 3 flow into the '+' operator, the result of which flows into the '*' operator, etc.
I understood what you meant, but it doesn't help. If the nodes and edges are constrained to operate on tables or even rows, you can't easily subvert them to operate on simple values. Certainly Knime won't allow it.
Ah, a limitation of KNIME.
So far, my efforts at using text expressions hinder transparency. With the EXTEND model you see the output of a node that adds a new value, but you can't see what it's inputs are except by parsing the text. I don't find that a sweet spot at all.
Different strokes for different folks, I guess.
I'm pondering a node that acts purely as a function. It takes a relation as input but chooses which attributes it will use as inputs/arguments. It outputs a relation comprising only the function arguments and result. It does not EXTEND an input relation, it merely computes a NEW VALUE. Then as per A and HHT, you are free to JOIN that output as you wish.
I don't mind the computed function being very simple and just picked from a list, or arbitrarily complex and written using a sub-language, as long as the inputs and outputs are transparent.
Yes, calling functions is reasonable, though if you integrate editing them into the environment you pretty much wind up with something like Rel's visual query language -- nodes for RA operators and text for scalar (and certain sub-) expressions.
The point is: getting away from the EXTEND paradigm. As per App-A and HHT you can model TIMES as a relation operator: relation in, relation out.
- The input is some relation with one or more numeric attributes, say
{{ A=3,B=7,other... },{ A=2,B=11,other...}, ...}- The output is
{{ A=3, B=7, C=21 },{ A=2,B=11,C=22}, ...}The output is join-compatible with the input.
I didn't know EXTEND was a paradigm; I thought it was an operator. Are you trying to get away from it because of other KNIME limitations?
Quote from dandl on March 21, 2020, 12:47 pmQuote from Dave Voorhis on March 21, 2020, 8:52 amQuote from dandl on March 20, 2020, 11:10 pmAn AST does not represent data flow, it is merely a diagrammatic representation of function application. LISP without the parentheses. Wrong paradigm.
No, but it can be subverted to become dataflow-like. Given an EXTEND expression like p := 2 * (y + 3), it obviously converts to an AST, but the AST is notionally akin to a dataflow something like:
[y] --\ [+] --\ [3] --/ [*] --> [p} [2] --------/I.e., the value of y and the value of the literal 3 flow into the '+' operator, the result of which flows into the '*' operator, etc.
I understood what you meant, but it doesn't help. If the nodes and edges are constrained to operate on tables or even rows, you can't easily subvert them to operate on simple values. Certainly Knime won't allow it.
Ah, a limitation of KNIME.
More a limitation of the dataflow paradigm. Knime has variables and loops and other stuff, but this is very much about seeing how far the pure dataflow can get.
So far, my efforts at using text expressions hinder transparency. With the EXTEND model you see the output of a node that adds a new value, but you can't see what it's inputs are except by parsing the text. I don't find that a sweet spot at all.
Different strokes for different folks, I guess.
I'm pondering a node that acts purely as a function. It takes a relation as input but chooses which attributes it will use as inputs/arguments. It outputs a relation comprising only the function arguments and result. It does not EXTEND an input relation, it merely computes a NEW VALUE. Then as per A and HHT, you are free to JOIN that output as you wish.
I don't mind the computed function being very simple and just picked from a list, or arbitrarily complex and written using a sub-language, as long as the inputs and outputs are transparent.
Yes, calling functions is reasonable, though if you integrate editing them into the environment you pretty much wind up with something like Rel's visual query language -- nodes for RA operators and text for scalar (and certain sub-) expressions.
The point is: getting away from the EXTEND paradigm. As per App-A and HHT you can model TIMES as a relation operator: relation in, relation out.
- The input is some relation with one or more numeric attributes, say
{{ A=3,B=7,other... },{ A=2,B=11,other...}, ...}- The output is
{{ A=3, B=7, C=21 },{ A=2,B=11,C=22}, ...}The output is join-compatible with the input.
I didn't know EXTEND was a paradigm; I thought it was an operator. Are you trying to get away from it because of other KNIME limitations?
There is nothing quite like EXTEND 'as an operator' in any other language I know, so it's hard to know exactly what abstraction it represents. It has a heritage in SQL, but it's much more powerful. As presented in TD it's Turing Complete, so it can be used to write unsafe and non-terminating queries, which is definitely not a normal expectation of the RA. I think the
New Valueoperator as described is powerful enough, while provably safe and terminating. It would certainly be interesting to extend its capabilities by embedding an AST-like tree structure of function calls inside the operator, while still staying safe and terminating. If you allow generalised scripting, all bets are off.
Quote from Dave Voorhis on March 21, 2020, 8:52 amQuote from dandl on March 20, 2020, 11:10 pmAn AST does not represent data flow, it is merely a diagrammatic representation of function application. LISP without the parentheses. Wrong paradigm.
No, but it can be subverted to become dataflow-like. Given an EXTEND expression like p := 2 * (y + 3), it obviously converts to an AST, but the AST is notionally akin to a dataflow something like:
[y] --\ [+] --\ [3] --/ [*] --> [p} [2] --------/I.e., the value of y and the value of the literal 3 flow into the '+' operator, the result of which flows into the '*' operator, etc.
I understood what you meant, but it doesn't help. If the nodes and edges are constrained to operate on tables or even rows, you can't easily subvert them to operate on simple values. Certainly Knime won't allow it.
Ah, a limitation of KNIME.
More a limitation of the dataflow paradigm. Knime has variables and loops and other stuff, but this is very much about seeing how far the pure dataflow can get.
So far, my efforts at using text expressions hinder transparency. With the EXTEND model you see the output of a node that adds a new value, but you can't see what it's inputs are except by parsing the text. I don't find that a sweet spot at all.
Different strokes for different folks, I guess.
I'm pondering a node that acts purely as a function. It takes a relation as input but chooses which attributes it will use as inputs/arguments. It outputs a relation comprising only the function arguments and result. It does not EXTEND an input relation, it merely computes a NEW VALUE. Then as per A and HHT, you are free to JOIN that output as you wish.
I don't mind the computed function being very simple and just picked from a list, or arbitrarily complex and written using a sub-language, as long as the inputs and outputs are transparent.
Yes, calling functions is reasonable, though if you integrate editing them into the environment you pretty much wind up with something like Rel's visual query language -- nodes for RA operators and text for scalar (and certain sub-) expressions.
The point is: getting away from the EXTEND paradigm. As per App-A and HHT you can model TIMES as a relation operator: relation in, relation out.
- The input is some relation with one or more numeric attributes, say
{{ A=3,B=7,other... },{ A=2,B=11,other...}, ...}- The output is
{{ A=3, B=7, C=21 },{ A=2,B=11,C=22}, ...}The output is join-compatible with the input.
I didn't know EXTEND was a paradigm; I thought it was an operator. Are you trying to get away from it because of other KNIME limitations?
There is nothing quite like EXTEND 'as an operator' in any other language I know, so it's hard to know exactly what abstraction it represents. It has a heritage in SQL, but it's much more powerful. As presented in TD it's Turing Complete, so it can be used to write unsafe and non-terminating queries, which is definitely not a normal expectation of the RA. I think the New Value operator as described is powerful enough, while provably safe and terminating. It would certainly be interesting to extend its capabilities by embedding an AST-like tree structure of function calls inside the operator, while still staying safe and terminating. If you allow generalised scripting, all bets are off.
Quote from Dave Voorhis on March 21, 2020, 2:39 pmQuote from dandl on March 21, 2020, 12:47 pmQuote from Dave Voorhis on March 21, 2020, 8:52 amQuote from dandl on March 20, 2020, 11:10 pmAn AST does not represent data flow, it is merely a diagrammatic representation of function application. LISP without the parentheses. Wrong paradigm.
No, but it can be subverted to become dataflow-like. Given an EXTEND expression like p := 2 * (y + 3), it obviously converts to an AST, but the AST is notionally akin to a dataflow something like:
[y] --\ [+] --\ [3] --/ [*] --> [p} [2] --------/I.e., the value of y and the value of the literal 3 flow into the '+' operator, the result of which flows into the '*' operator, etc.
I understood what you meant, but it doesn't help. If the nodes and edges are constrained to operate on tables or even rows, you can't easily subvert them to operate on simple values. Certainly Knime won't allow it.
Ah, a limitation of KNIME.
More a limitation of the dataflow paradigm. Knime has variables and loops and other stuff, but this is very much about seeing how far the pure dataflow can get.
So far, my efforts at using text expressions hinder transparency. With the EXTEND model you see the output of a node that adds a new value, but you can't see what it's inputs are except by parsing the text. I don't find that a sweet spot at all.
Different strokes for different folks, I guess.
I'm pondering a node that acts purely as a function. It takes a relation as input but chooses which attributes it will use as inputs/arguments. It outputs a relation comprising only the function arguments and result. It does not EXTEND an input relation, it merely computes a NEW VALUE. Then as per A and HHT, you are free to JOIN that output as you wish.
I don't mind the computed function being very simple and just picked from a list, or arbitrarily complex and written using a sub-language, as long as the inputs and outputs are transparent.
Yes, calling functions is reasonable, though if you integrate editing them into the environment you pretty much wind up with something like Rel's visual query language -- nodes for RA operators and text for scalar (and certain sub-) expressions.
The point is: getting away from the EXTEND paradigm. As per App-A and HHT you can model TIMES as a relation operator: relation in, relation out.
- The input is some relation with one or more numeric attributes, say
{{ A=3,B=7,other... },{ A=2,B=11,other...}, ...}- The output is
{{ A=3, B=7, C=21 },{ A=2,B=11,C=22}, ...}The output is join-compatible with the input.
I didn't know EXTEND was a paradigm; I thought it was an operator. Are you trying to get away from it because of other KNIME limitations?
There is nothing quite like EXTEND 'as an operator' in any other language I know, so it's hard to know exactly what abstraction it represents. It has a heritage in SQL, but it's much more powerful. As presented in TD it's Turing Complete, so it can be used to write unsafe and non-terminating queries, which is definitely not a normal expectation of the RA.
True, but TD is a conventional programming language with database capabilities, rather than a query language.
The abstraction EXTEND represents is EXTEND.
Quote from dandl on March 21, 2020, 12:47 pmQuote from Dave Voorhis on March 21, 2020, 8:52 amQuote from dandl on March 20, 2020, 11:10 pmAn AST does not represent data flow, it is merely a diagrammatic representation of function application. LISP without the parentheses. Wrong paradigm.
No, but it can be subverted to become dataflow-like. Given an EXTEND expression like p := 2 * (y + 3), it obviously converts to an AST, but the AST is notionally akin to a dataflow something like:
[y] --\ [+] --\ [3] --/ [*] --> [p} [2] --------/I.e., the value of y and the value of the literal 3 flow into the '+' operator, the result of which flows into the '*' operator, etc.
I understood what you meant, but it doesn't help. If the nodes and edges are constrained to operate on tables or even rows, you can't easily subvert them to operate on simple values. Certainly Knime won't allow it.
Ah, a limitation of KNIME.
More a limitation of the dataflow paradigm. Knime has variables and loops and other stuff, but this is very much about seeing how far the pure dataflow can get.
So far, my efforts at using text expressions hinder transparency. With the EXTEND model you see the output of a node that adds a new value, but you can't see what it's inputs are except by parsing the text. I don't find that a sweet spot at all.
Different strokes for different folks, I guess.
I'm pondering a node that acts purely as a function. It takes a relation as input but chooses which attributes it will use as inputs/arguments. It outputs a relation comprising only the function arguments and result. It does not EXTEND an input relation, it merely computes a NEW VALUE. Then as per A and HHT, you are free to JOIN that output as you wish.
I don't mind the computed function being very simple and just picked from a list, or arbitrarily complex and written using a sub-language, as long as the inputs and outputs are transparent.
Yes, calling functions is reasonable, though if you integrate editing them into the environment you pretty much wind up with something like Rel's visual query language -- nodes for RA operators and text for scalar (and certain sub-) expressions.
The point is: getting away from the EXTEND paradigm. As per App-A and HHT you can model TIMES as a relation operator: relation in, relation out.
- The input is some relation with one or more numeric attributes, say
{{ A=3,B=7,other... },{ A=2,B=11,other...}, ...}- The output is
{{ A=3, B=7, C=21 },{ A=2,B=11,C=22}, ...}The output is join-compatible with the input.
I didn't know EXTEND was a paradigm; I thought it was an operator. Are you trying to get away from it because of other KNIME limitations?
There is nothing quite like EXTEND 'as an operator' in any other language I know, so it's hard to know exactly what abstraction it represents. It has a heritage in SQL, but it's much more powerful. As presented in TD it's Turing Complete, so it can be used to write unsafe and non-terminating queries, which is definitely not a normal expectation of the RA.
True, but TD is a conventional programming language with database capabilities, rather than a query language.
The abstraction EXTEND represents is EXTEND.
Quote from Erwin on March 21, 2020, 4:57 pmQuote from dandl on March 21, 2020, 12:47 pmAs presented in TD [EXTEND] is Turing Complete, so it can be used to write unsafe and non-terminating queries.
I'm curious. You have an example of a query where the EXTEND is "unsafe" or "non-terminating" ? Or an idea of the kind of strategy one would have to follow if one wanted to actually write one such ?
Only way I see is to include an "unsafe" or "non-terminating" expression in the extend list itself. But that is not a problem of the RA part, that's a problem of the "scalar algebra" part ...
Quote from dandl on March 21, 2020, 12:47 pmAs presented in TD [EXTEND] is Turing Complete, so it can be used to write unsafe and non-terminating queries.
I'm curious. You have an example of a query where the EXTEND is "unsafe" or "non-terminating" ? Or an idea of the kind of strategy one would have to follow if one wanted to actually write one such ?
Only way I see is to include an "unsafe" or "non-terminating" expression in the extend list itself. But that is not a problem of the RA part, that's a problem of the "scalar algebra" part ...
Quote from Dave Voorhis on March 21, 2020, 5:11 pmQuote from Erwin on March 21, 2020, 4:57 pmQuote from dandl on March 21, 2020, 12:47 pmAs presented in TD [EXTEND] is Turing Complete, so it can be used to write unsafe and non-terminating queries.
I'm curious. You have an example of a query where the EXTEND is "unsafe" or "non-terminating" ? Or an idea of the kind of strategy one would have to follow if one wanted to actually write one such ?
I thought he meant TD is Turing Complete. If he meant EXTEND, then I have the same question.
Edit: I re-read it, and indeed it suggests EXTEND in TD is Turing Complete, by which I assume he meant that you can invoke an arbitrary function which may not terminate.
Which is true, but I don't know of any practical language, query or programming, that prevents non-termination.
Quote from Erwin on March 21, 2020, 4:57 pmQuote from dandl on March 21, 2020, 12:47 pmAs presented in TD [EXTEND] is Turing Complete, so it can be used to write unsafe and non-terminating queries.
I'm curious. You have an example of a query where the EXTEND is "unsafe" or "non-terminating" ? Or an idea of the kind of strategy one would have to follow if one wanted to actually write one such ?
I thought he meant TD is Turing Complete. If he meant EXTEND, then I have the same question.
Edit: I re-read it, and indeed it suggests EXTEND in TD is Turing Complete, by which I assume he meant that you can invoke an arbitrary function which may not terminate.
Which is true, but I don't know of any practical language, query or programming, that prevents non-termination.
Quote from dandl on March 22, 2020, 12:37 amQuote from Erwin on March 21, 2020, 4:57 pmQuote from dandl on March 21, 2020, 12:47 pmAs presented in TD [EXTEND] is Turing Complete, so it can be used to write unsafe and non-terminating queries.
I'm curious. You have an example of a query where the EXTEND is "unsafe" or "non-terminating" ? Or an idea of the kind of strategy one would have to follow if one wanted to actually write one such ?
Only way I see is to include an "unsafe" or "non-terminating" expression in the extend list itself. But that is not a problem of the RA part, that's a problem of the "scalar algebra" part ...
As far as I know any query in TD is 'unsafe', in the sense that it may fail to terminate, may return different outputs for identical inputs or may trigger an arbitrary error. EXTEND is just a special case of 'unsafeness' because the new value is provided by the invocation of an operator, which itself is 'unsafe'.
The particular language features responsible include loops, recursion, global state accessible to local scope, and language constructs that trigger runtime errors. My knowledge of TD is limited, so feel free to correct me. Query languages without these features can be made 'safe'. Alice discusses this.
I thought that was common knowledge, but feel free to correct me.
Quote from Erwin on March 21, 2020, 4:57 pmQuote from dandl on March 21, 2020, 12:47 pmAs presented in TD [EXTEND] is Turing Complete, so it can be used to write unsafe and non-terminating queries.
I'm curious. You have an example of a query where the EXTEND is "unsafe" or "non-terminating" ? Or an idea of the kind of strategy one would have to follow if one wanted to actually write one such ?
Only way I see is to include an "unsafe" or "non-terminating" expression in the extend list itself. But that is not a problem of the RA part, that's a problem of the "scalar algebra" part ...
As far as I know any query in TD is 'unsafe', in the sense that it may fail to terminate, may return different outputs for identical inputs or may trigger an arbitrary error. EXTEND is just a special case of 'unsafeness' because the new value is provided by the invocation of an operator, which itself is 'unsafe'.
The particular language features responsible include loops, recursion, global state accessible to local scope, and language constructs that trigger runtime errors. My knowledge of TD is limited, so feel free to correct me. Query languages without these features can be made 'safe'. Alice discusses this.
I thought that was common knowledge, but feel free to correct me.
Quote from dandl on March 22, 2020, 12:55 amWhich is true, but I don't know of any practical language, query or programming, that prevents non-termination.
I was under the impression that SQL queries, including fix-point recursion in CTE, always terminate. [I'm specifically excluding SQL procedural variants.] SQL is highly practical, even though there are queries beyond its capabilities.
An SQL query has no state other than the database (unless you want to include database 'settings' too). SQL queries can fail of course, but usually for highly predictable reasons. Does that make them 'unsafe'?
Which is true, but I don't know of any practical language, query or programming, that prevents non-termination.
I was under the impression that SQL queries, including fix-point recursion in CTE, always terminate. [I'm specifically excluding SQL procedural variants.] SQL is highly practical, even though there are queries beyond its capabilities.
An SQL query has no state other than the database (unless you want to include database 'settings' too). SQL queries can fail of course, but usually for highly predictable reasons. Does that make them 'unsafe'?
Quote from Dave Voorhis on March 22, 2020, 1:01 amQuote from dandl on March 22, 2020, 12:55 amWhich is true, but I don't know of any practical language, query or programming, that prevents non-termination.
I was under the impression that SQL queries, including fix-point recursion in CTE, always terminate. [I'm specifically excluding SQL procedural variants.] SQL is highly practical, even though there are queries beyond its capabilities.
An SQL query has no state other than the database (unless you want to include database 'settings' too). SQL queries can fail of course, but usually for highly predictable reasons. Does that make them 'unsafe'?
I was assuming SQL with at least user-defined functions, because I don't think there are any practical (and popular) SQL implementations without them. Except SQLite, maybe?
But it supports calling functions in the host language, so it's effectively as non-terminant as the others.
Quote from dandl on March 22, 2020, 12:55 amWhich is true, but I don't know of any practical language, query or programming, that prevents non-termination.
I was under the impression that SQL queries, including fix-point recursion in CTE, always terminate. [I'm specifically excluding SQL procedural variants.] SQL is highly practical, even though there are queries beyond its capabilities.
An SQL query has no state other than the database (unless you want to include database 'settings' too). SQL queries can fail of course, but usually for highly predictable reasons. Does that make them 'unsafe'?
I was assuming SQL with at least user-defined functions, because I don't think there are any practical (and popular) SQL implementations without them. Except SQLite, maybe?
But it supports calling functions in the host language, so it's effectively as non-terminant as the others.